

因為文本賦值或者進(jìn)行加減法賦值固定位數(shù)的時候比較困難,使用這個代碼的話就可以在文本型字段下進(jìn)行9位數(shù)的流水號賦值:
max = 121 #從某個號開始流水號
def LSH(XZ):
global maxXZ = XZ.strip()if XZ == None or XZ == "": max = max + 1 return str(max).zfill(9)else: return XZ使用方法如下: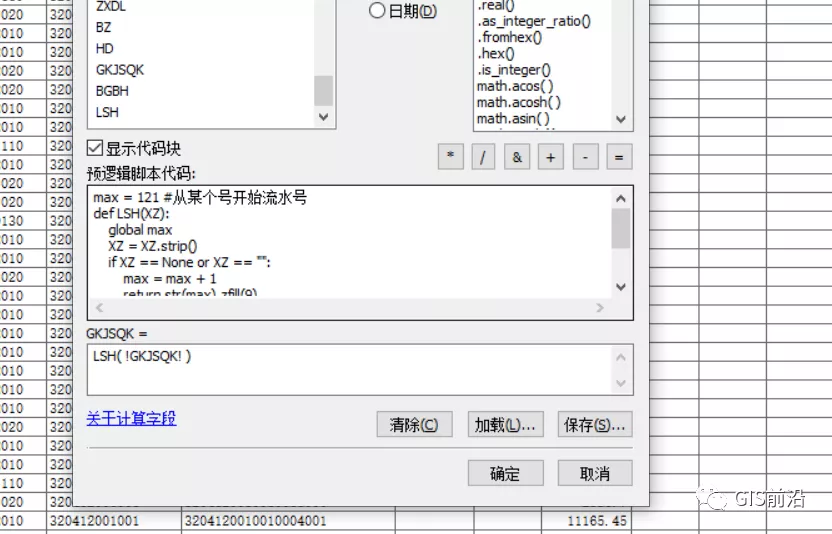
具體功能:對某個字段進(jìn)行流水號賦值及其進(jìn)行9位數(shù)的流水號賦值及確認(rèn)某號開始流水,在農(nóng)經(jīng)權(quán)、房屋一體化及各類權(quán)證工作中及其有效!
做數(shù)據(jù)二級或多級分類的時候,一個一個的數(shù)據(jù)融合太過于苦惱,例如耕地(按照資源部給出的定義為:水田、旱地、水澆地),當(dāng)我要對地類二級分類的時候,豈不是要對數(shù)據(jù)做五六次融合以及好多次數(shù)據(jù)篩選?
對于懶人來說,這怎么可以!
對于工作精英來說,這種小事浪費這么多時間,真是對自己能力的一種褻瀆。
咳咳,回到正題。
基于這種考慮,我們做了這樣幾行代碼,如下:
def a(b)
if b == u"旱地"
return “耕地”
elif b == u"水田"
return “耕地”
elif b == u"水澆地"
return “耕地”
else
return"非耕地"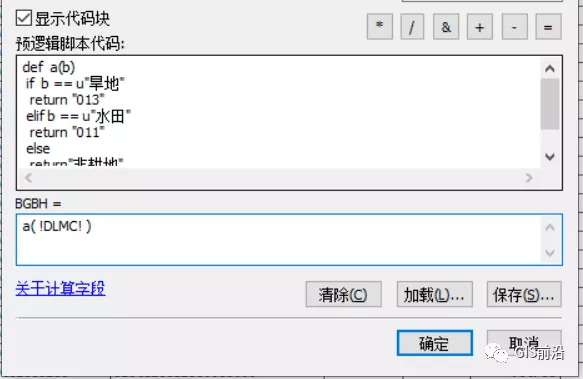
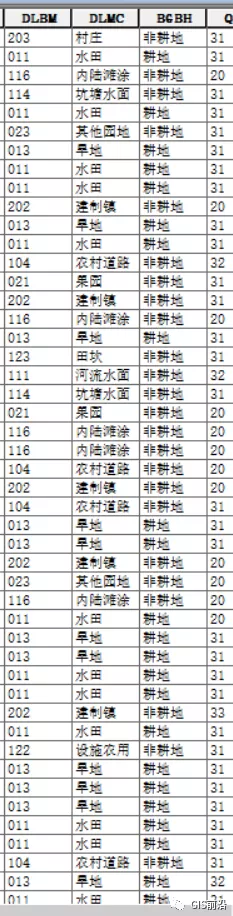
這是更新過后的字段,這樣再提取耕地數(shù)據(jù)就輕而易舉了
關(guān)于這個的應(yīng)用場景呢,主要是基于一個項目的需求,要求做把地類分為耕地與非耕地兩種類型,我們先新建一個分類字段,設(shè)置為字符串類型(即文本型),再根據(jù)DLMC進(jìn)行類型識別,如果是旱地、水田、水澆地就屬于耕地,不是則屬于非耕地;再根據(jù)屬性字段提取矢量數(shù)據(jù)就可以得到耕地數(shù)據(jù)及非耕地數(shù)據(jù)。
來源:https://blog.csdn.net/qq_43173805/article/details/121184590成都途遠(yuǎn)GIS是一家專業(yè)致力于無人機(jī)航空攝影測繪、航空數(shù)據(jù)處理、GIS地理信息系統(tǒng)研發(fā)、數(shù)字孿生城市制作、數(shù)字沙盤模型等業(yè)務(wù)的創(chuàng)新型科技公司,為您提供一站式地理信息服務(wù)。
本文鏈接:http://www.aiquka.com/blog/431.html
本文標(biāo)簽:ArcGIS











