

為了充分融合不同深度學習模型在建筑提取中的互補信息,該文提出一種基于深度學習概率決策融合的高分辨率影像建筑物提取方法,將不同深度學習模型的類別分割概率進行融合作為最終建筑提取的依據(jù),以實現(xiàn)不同模型之間的優(yōu)勢互補,最后采用形態(tài)學后處理方法進一步優(yōu)化建筑提取結(jié)果。采用3組不同分辨率,具有多種地物形態(tài)的建筑數(shù)據(jù)集驗證本文方法的有效性。實驗表明該文提出的概率決策融合方法取得了滿意的精度(F指數(shù)分別為92.45%,90.56%,79.95%),優(yōu)于單一模型的結(jié)果,并且顯著提升了建筑提取結(jié)果的可靠性。
引言
建筑是城市最主要的地物類型之一,建筑信息的準確提取對城市規(guī)劃管理、人口密度估計和自然災(zāi)害評估等方面具有重要意義[1]。高分辨率影像具有豐富的地物細節(jié)信息,能夠區(qū)分建筑、道路等城市基本地物,為大范圍的建筑物提取提供了可能性。過去幾十年,高分辨率影像建筑信息提取一直是遙感和計算機視覺領(lǐng)域的熱點研究問題,吸引著眾多學者的關(guān)注[2]。
當前,建筑提取的方法主要包括自動提取方法,傳統(tǒng)的監(jiān)督分類方法和深度學習方法。建筑的自動提取主要采用基于知識和規(guī)則的方法,根據(jù)建筑物的光譜、紋理、形狀、空間關(guān)系等基本特征,構(gòu)建建筑提取的規(guī)則[3]。比如建筑與附近的地物之間會形成較高的局部對比度,建筑和陰影存在空間共生關(guān)系。基于這些規(guī)則,一些學者構(gòu)建了自動化的建筑指數(shù),如形態(tài)學建筑指數(shù)(morphological building index, MBI)和建筑區(qū)域指數(shù)PanTex[2, 4]。監(jiān)督分類方法依賴于一定人力的樣本標記和搜集,由于可以從訓練樣本中獲得先驗知識,監(jiān)督分類方法能夠更好地應(yīng)對復雜場景下的建筑提取。傳統(tǒng)的監(jiān)督分類方法多采用多特征融合的機器學習方法,其關(guān)鍵也是在于設(shè)計有效的特征來描述建筑的屬性。除了光譜特征之外,空間特征常常被用來彌補高分辨率影像上光譜特征對建筑屬性描述的不足。常用的空間特征包括形態(tài)學差分譜[5]、灰度共生矩陣[6](gray-level co-occurance matrix, GLCM)等。然而,以上方法主要采用人工設(shè)計特征,依賴于專家知識。而且,由于建筑自身和環(huán)境的復雜性,人為設(shè)計的底層特征在描述建筑屬性時,依然存在巨大挑戰(zhàn)。
近些年來,基于卷積神經(jīng)網(wǎng)絡(luò)(convolutional neural network, CNN)的深度學習方法已經(jīng)越來越多地應(yīng)用于計算機視覺和圖像處理領(lǐng)域,并且取得了巨大的成功。相對于傳統(tǒng)的特征工程方法,深度學習是一種數(shù)據(jù)驅(qū)動的模型,它擁有強大的特征學習和表征能力,能夠從標記數(shù)據(jù)中自動學得中高層的抽象特征[7]。建筑提取在計算機視覺領(lǐng)域可以看成是一個語義分割問題,即對影像上的建筑物與非建筑物進行像素級的類別標記區(qū)分。目前,眾多典型的CNN模型,如全卷積神經(jīng)網(wǎng)絡(luò)(fully convolutional network,F(xiàn)CN)[8]、 Segnet [9]、U-net [10]、 Deeplab系列[11]等,已經(jīng)成功應(yīng)用于影像的語義分割任務(wù)。其中,基于深度學習的高分辨率影像建筑提取研究,也取得了一定進展。比如:文獻[12]采用兩步法CNN模型從高分辨率影像上提取鄉(xiāng)村的建筑。該方法第一階段在粗尺度上進行村莊的定位與提取,隨后在村莊區(qū)域進行精細尺度的單個建筑提取。該方法能夠減少影像背景的復雜性,提升鄉(xiāng)村建筑的提取效率。文獻[13]提出一種基于深度殘差網(wǎng)絡(luò)的模型用于建筑探測,同時采用面向?qū)ο蟮臑V波方法進一步優(yōu)化建筑提取結(jié)果。文獻[14]采用Deeplab-v3+模型對遙感影像進行了建筑的分割。
CNN模型眾多,不同模型的構(gòu)建方式也不盡相同,針對高分辨率影像上建筑提取這個特定任務(wù),不同的CNN模型可能表現(xiàn)出不同的優(yōu)勢,融合不同深度模型的結(jié)果有望進一步優(yōu)化。因此,本文提出一種基于深度學習概率決策融合的建筑提取方法,在決策層融合不同模型的類別分割概率作為最終類別標記的依據(jù),以期不同的CNN模型能夠優(yōu)勢互補,提升建筑提取的精度與置信度,最后根據(jù)建筑幾何屬性,采用后處理操作,進一步優(yōu)化建筑提取結(jié)果。
建筑提取方法
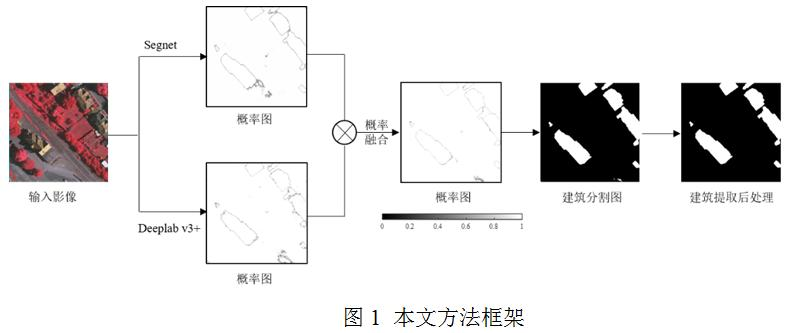
圖1展示了本文的方法框架。首先,采用不同的卷積神經(jīng)網(wǎng)絡(luò)(本文選取Segnet和Deeplab v3+兩個典型網(wǎng)絡(luò))對影像進行語義分割,生成類別概率圖;然后,在決策層融合不同網(wǎng)絡(luò)模型的類別概率來實現(xiàn)不同模型的優(yōu)勢互補,提升建筑提取的精度與可靠性;最后,根據(jù)建筑物的幾何信息,采用必要的后處理操作對建筑提取結(jié)果進一步優(yōu)化得到比較純凈的建筑信息。
文獻[15]在2015年提出FCN,實現(xiàn)了基于端到端的CNN圖像語義分割。FCN使用卷積層替換CNN中的全連接層,可以接受任意尺寸的輸入圖像。為了使影像的輸出與輸入大小相同,F(xiàn)CN將特征圖上采樣到與輸入圖像相同的尺寸,同時融合淺層網(wǎng)絡(luò)學習到的特征,得到更好的分割結(jié)果。在FCN的引領(lǐng)下,基于CNN的語義分割方法開始蓬勃發(fā)展,出現(xiàn)了Segnet、 U-net、 Deeplab系列等。這些網(wǎng)絡(luò)實現(xiàn)方式不同,在具體的語義分割任務(wù)中,可能有各自的優(yōu)勢。因此,對它們的結(jié)果進行融合,有望實現(xiàn)優(yōu)勢互補,進一步優(yōu)化分割結(jié)果。本文將以典型的語義分割網(wǎng)絡(luò)Segnet和Deeplab v3+為例,探索概率決策融合對高分辨率影像建筑識別的有效性。下面簡要介紹Segnet和Deeplab v3+的基本原理。
Segnet
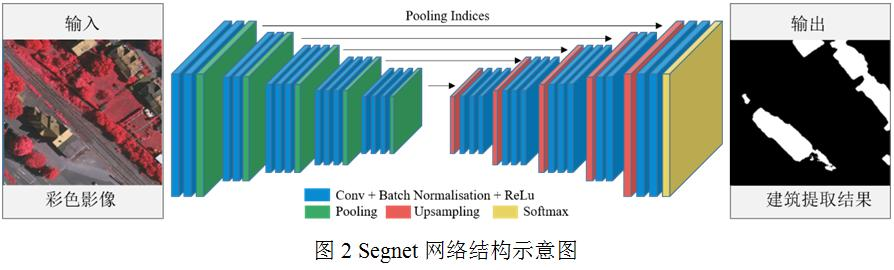
Segnet是一個經(jīng)典的語義分割網(wǎng)絡(luò)模型,該模型使用了“編碼-解碼”的對稱結(jié)構(gòu)[8](圖2)。其中,編碼器是指網(wǎng)絡(luò)的特征提取部分,使用卷積層和池化層逐漸縮小圖像的尺寸,編碼器網(wǎng)絡(luò)結(jié)構(gòu)可采用去除全連接層的VGG-16網(wǎng)絡(luò)[16]。解碼器是指將特征圖轉(zhuǎn)化為預(yù)測圖的部分,使用了一系列的上采樣和卷積操作,其結(jié)構(gòu)的關(guān)鍵之處在于解碼階段用到了編碼器在池化時的索引值,從而能以原有的信息進行上采樣,恢復目標的邊緣位置,得到更加準確的分割結(jié)果。
Deeplab v3+
Deeplab v3+是Deeplab系列模型的最新版本,自從文獻[17]采用空洞卷積算法,提出deeplab v1以來,作者不斷推陳出新,探索ResNet[18]和Xception[19]等模型作為不同的特征提取器,引入帶孔的空間金字塔模塊(atrous spatial pyramid pooling, ASPP)和編碼-解碼結(jié)構(gòu)[20],對原有模型進行進一步的改進。ASPP包含不同尺度的帶孔卷積核對圖像進行處理,能夠挖掘圖像的多尺度和上下文內(nèi)容信息,提取影像的高層特征。為了防止目標邊界信息因為池化和卷積操作而丟失,引入的編碼-解碼器結(jié)構(gòu)可以通過逐步恢復空間信息來獲得更清晰的目標邊界。綜上,Deeplab v3+通過采用ASPP模塊和編碼-解碼結(jié)構(gòu),處理多尺度的圖像上下文信息,優(yōu)化分割結(jié)果,提高目標的分割精度。2
概率決策融合與置信度
語義分割模型眾多,不同的模型實現(xiàn)方式和技巧有著較大的區(qū)別,針對一個具體的語義分割任務(wù),不同的網(wǎng)絡(luò)模型可能擁有各自的優(yōu)勢。因此,本文認為將不同模型進行融合有望實現(xiàn)模型之間的優(yōu)勢互補,從而進一步提升模型的影像分割精度。具體地,本文認為Segnet和Deeplab v3+模型在高分辨率影像建筑識別的任務(wù)中,能夠提取到互補的信息。考慮到深度學習在預(yù)測時不僅能夠直接輸出類別標簽,也能夠得到每個像素屬于每個類別的概率信息,因此,本文將不同語義分割模型獨立輸出的類別概率進行決策層的概率融合,根據(jù)融合概率確定最終的類別標記結(jié)果,以提升建筑提取的精度。概率融合公式表示如下:

需要說明的是,概率決策融合方法可以看成是一種框架,它可以融合不同的語義分割模型,本文只是以Segnet和Deeplab v3+為例,探究模型融合的有效性。
為進一步探究概率融合的效果,本文從分類置信度角度繼續(xù)分析。對于二類分割任務(wù),分類概率可以直接衡量某個類別的分割置信度,分類概率值越大,表明該像素分類置信度越高。本文統(tǒng)計不同CNN模型以及融合模型中高置信度分類結(jié)果的比例,探究概率融合對分類置信度的影響。具體地,本文設(shè)置9為高置信度分割結(jié)果。初始的建筑提取結(jié)果一般會包含細小的噪聲、對象孔洞等,影響了建筑提取的精度。根據(jù)建筑屬性認知,本文采用面積約束和建筑孔洞填充進一步對初始建筑提取結(jié)果進行后處理優(yōu)化。具體地,若某一探測的建筑對象的面積小于給定閾值c,則該對象被標記為背景;若建筑孔洞局部半徑小于給定閾值r,則對該孔洞進行形態(tài)學重構(gòu)運算進行填充并且保持該建筑對象的邊緣[21]。面積約束能夠減少建筑提取的錯檢誤差,建筑孔洞填充能夠減少建筑提取的遺漏誤差,從而整體上提高建筑檢測的精度。考慮到建筑物的幾何屬性,本實驗中,最小建筑的面積閾值c設(shè)為5 m2,建筑孔洞局部半徑閾值r設(shè)為2 m,對應(yīng)形態(tài)學運算的圓形結(jié)構(gòu)元素半徑大小。
本文采用準確率(P)、召回率(R)和F指數(shù)(F)3個常用的指標來衡量建筑提取的精度。其中,準確率可以衡量建筑提取的正確率,召回率反映建筑提取的完備率,F(xiàn)指數(shù)是同時考慮建筑提取準確性與完備性的綜合指標。3個指標的定義公式如下:

式中:TP表示正類預(yù)測為正類,即正確檢測的建筑,F(xiàn)P表示將負類預(yù)測為正類,即錯誤檢測的建筑,對應(yīng)錯分誤差;FN表示正類預(yù)測為負類,即遺漏的建筑,對應(yīng)漏分誤差;表示像素個數(shù)。
實驗與分析本文采用了3種不同分辨率的建筑數(shù)據(jù)集進行實驗(圖3),分別是國際攝影測量與遙感協(xié)會(International Society for Photogrammetry and RemoteSensing, ISPRS)的Vaihingen建筑數(shù)據(jù)集,分辨率0.09 m(http://www2.isprs.org/commissions/comm3/wg4/2d-sem-label-vaihingen.html),武漢大學季順平團隊生產(chǎn)的建筑數(shù)據(jù)集(WHU Building),分辨率0.3 m(http://study.rsgis.whu.edu.cn/pages/download/),馬薩諸塞州建筑數(shù)據(jù)集(Massachusetts Building),分辨率1 m(https://www.cs.toronto.edu/~vmnih/data/)。ISPRS Vaihingen數(shù)據(jù)集包含近紅外和紅綠共3個波段,一共有33個不同大小的影像區(qū)域(尺寸大約在2 500像素×2 500像素左右),其中16個區(qū)域為訓練影像,其它17個區(qū)域為測試影像。WHU Building數(shù)據(jù)集包含4 736個訓練樣本塊,1 036個驗證樣本塊,2 416個測試樣本塊,大小都為512像素×512像素。MassachusettsBuilding數(shù)據(jù)集包含103個訓練影像,4個驗證影像,10個測試影像,影像大小都為1 500像素×1 500像素。
考慮到電腦內(nèi)存,在訓練階段,本文將ISPRS Vaihingen的訓練集裁剪為500像素×500像素的規(guī)則影像塊,裁剪步長為100像素,隨機選擇其中80%的圖像塊作為訓練數(shù)據(jù),其余作為驗證數(shù)據(jù)。
Massachusetts Building的數(shù)據(jù)集和驗證集也被裁剪成500×500像素的規(guī)則影像塊,裁剪步長為200像素。在模型預(yù)測階段,內(nèi)存消耗相對較少,并且語義分割網(wǎng)絡(luò)可以接受任意尺寸的圖像輸入,ISPRS Vaihingen和Massachusetts Building數(shù)據(jù)集的原始測試影像均可直接輸入到訓練好的模型中進行預(yù)測。表 1和圖3展示了具體的數(shù)據(jù)集信息。
在訓練過程中,對訓練樣本進行了數(shù)據(jù)增強處理,如平移、翻轉(zhuǎn)等操作。Segnet和Deeplab v3+分別采用預(yù)訓練的VGG-16 [16]和ResNet-18 [18]作為網(wǎng)絡(luò)骨架,采用動量梯度隨機下降法(stochastic gradient descent with momentum, SGDM)進行訓練,本文在實驗過程中對CNN的訓練參數(shù)進行了調(diào)試優(yōu)化,同時也參考現(xiàn)有文獻中的參數(shù)設(shè)置,動量參數(shù)設(shè)為0.9,初始學習率為0.001,batch size大小為4,訓練輪數(shù)為100,在訓練過程中,每500次迭代做一次精度驗證。從網(wǎng)絡(luò)的中間訓練過程(圖4)以及最終的測試結(jié)果來看,這些CNN模型的網(wǎng)絡(luò)配置是較優(yōu)合理的。


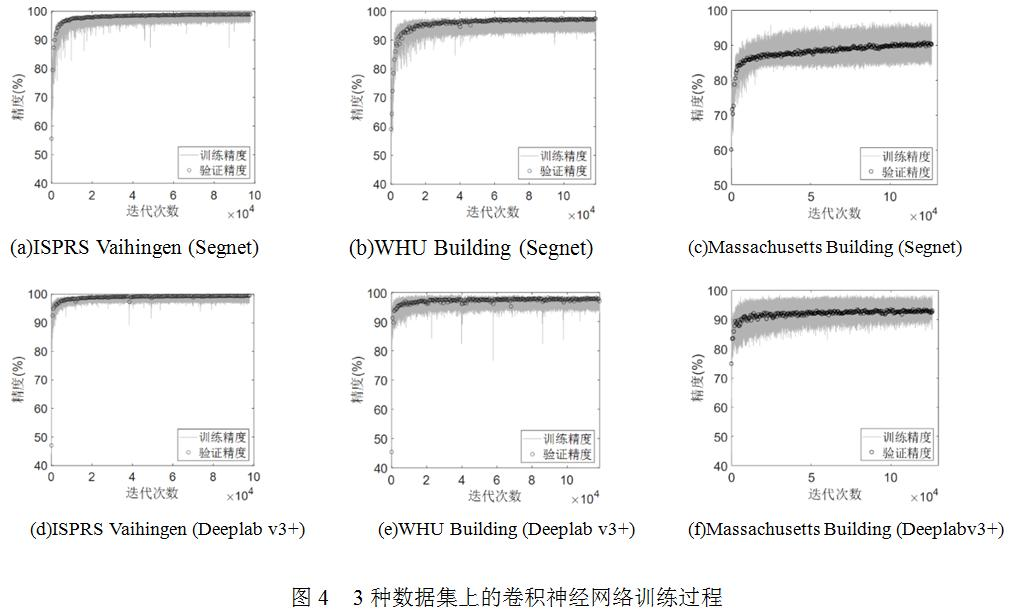
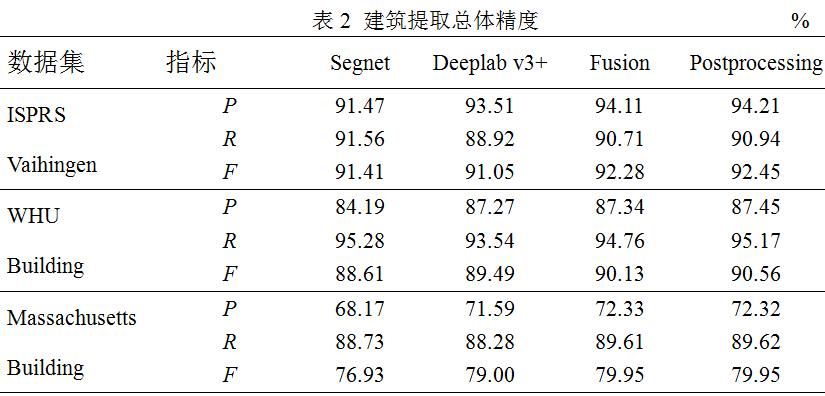
表2展示了建筑提取的精度,可以看到Segnet和Deeplab v3+模型在ISPRS Vaihingen和WHU Building數(shù)據(jù)集上表現(xiàn)較好,F(xiàn)指數(shù)達到了90%左右,在Massachusetts Building數(shù)據(jù)集上精度相對較低,F(xiàn)指數(shù)約為80%。對于ISPRS Vaihingen和WHU Building數(shù)據(jù)集,影像分辨率非常高,建筑物與其它地物區(qū)分比較明顯,建筑的邊緣比較清晰,而Massachusetts Building數(shù)據(jù)集,分辨率相對較低,建筑目標比較模糊,和周圍地物容易混淆,可能影響建筑提取精度。此外,本文注意到兩種CNN模型在P和R 2個指標上互有優(yōu)勢,因此,融合兩種模型有望實現(xiàn)優(yōu)勢互補。可以看到,本文提出的概率決策融合方法在F指數(shù)上取得了優(yōu)于單一模型的結(jié)果,3個數(shù)據(jù)集上的精度分別達到了92.28%、90.13%和79.95%。這說明本文提出的概率決策融合模型用于高分辨率影像建筑提取的有效性。在此基礎(chǔ)上進行形態(tài)學后處理(去噪聲、補孔洞)操作,也能夠進一步提升建筑提取精度,F(xiàn)指數(shù)分別達到了92.45%、90.56%和79.95%。但本文也注意到Massachusetts Building數(shù)據(jù)集的后處理精度幾乎沒有變化,這可能是因為在較低分辨率影像上,地物的細節(jié)和異質(zhì)性相對較少,建筑初提取結(jié)果中的虛警噪聲和建筑內(nèi)部的孔洞現(xiàn)象較少。這種情況下,采用的形態(tài)學后處理方法對該數(shù)據(jù)影響有限。
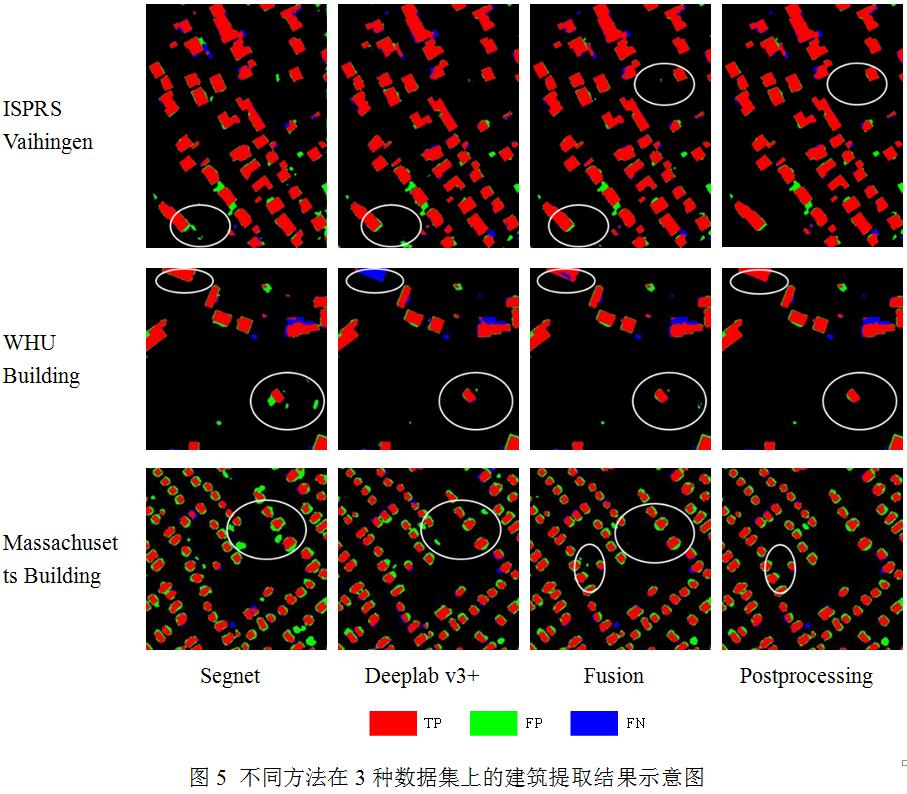
圖5展示了建筑提取結(jié)果及其精度圖,可以看到大部分建筑對象都得到了正確的識別。在ISPRS Vaihingen和Massachusetts Building數(shù)據(jù)集的標識區(qū)域內(nèi),Segnet和Deeplab v3+模型在不同地方產(chǎn)生了虛警,但是兩者融合后,虛警都被減弱了,并且后處理進一步濾除了細小的噪聲,提升了建筑提取的準確率。此外,在WHU Building數(shù)據(jù)集的標識區(qū)域內(nèi),Segnet和Deeplab v3+模型分別表現(xiàn)出一些錯檢和遺漏誤差,概率決策融合后,2種誤差都得到了緩解,經(jīng)過后處理,建筑對象內(nèi)部的小孔洞也被填充,提升了建筑提取的完備率。
綜上,本文提出的概率決策融合方法在不同分辨率的數(shù)據(jù)集上都取得了比單一模型較優(yōu)的結(jié)果。此外,形態(tài)學后處理操作能夠進一步優(yōu)化建筑提取結(jié)果。考慮到建筑的實際大小和建筑在影像上的可區(qū)分能力,并結(jié)合本文的實驗結(jié)果,認為當影像分辨率優(yōu)于1 m時,比較有利于建筑物的準確提取。
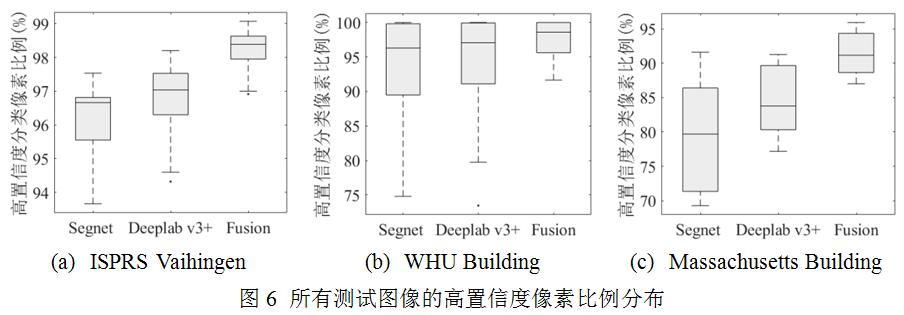
為分析概率決策融合的模型對類別分割置信度的影響,本文統(tǒng)計了每個數(shù)據(jù)集的所有測試圖像在不同模型下的高置信度(分類概率大于0.9)分類像素的比例,并繪制箱型圖如圖6所示。可以看出來,概率決策融合模型顯著提升了分割結(jié)果中高置信度像素的比例。比如,在ISPRS Vaihingen數(shù)據(jù)集中,高置信度像素比例分布的中值由96.6%(Segnet)和97.0%(Deeplab v3+)提升到98.3%(融合模型)。
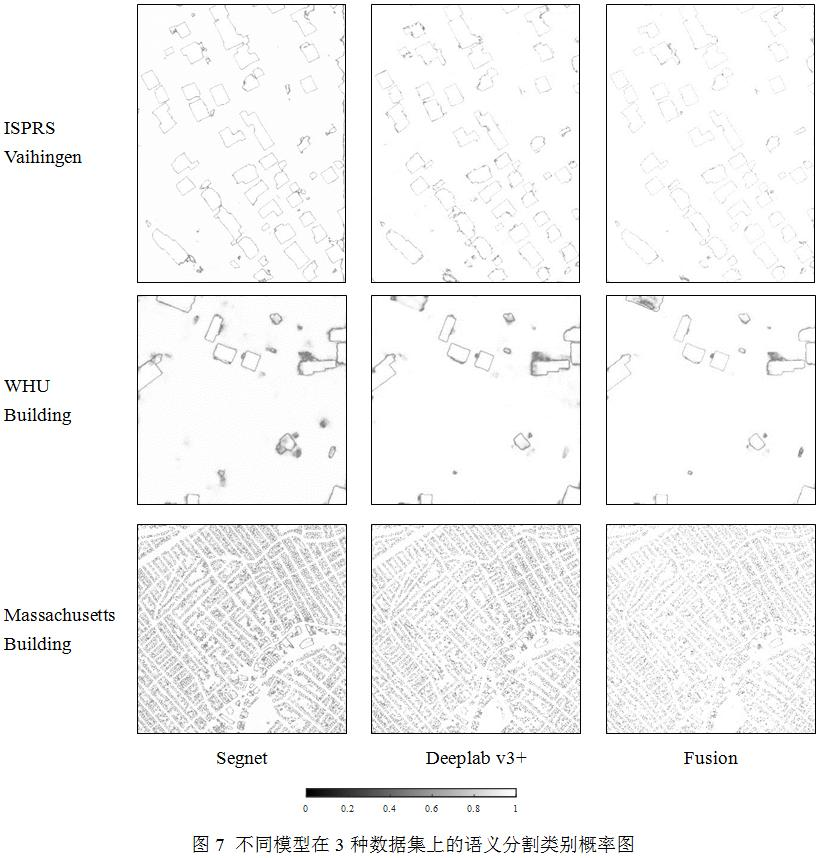
圖7展示了不同模型輸出的分類置信度圖,可以看出來,高置信度的像素主要分布于建筑與背景類別的內(nèi)部,而置信度較低的像素主要集中在類別間的邊界區(qū)域,邊界區(qū)域由于混合了建筑與背景類別的特征,因此分類的可靠性較低。但是,從整體的置信度圖目視效果來看,融合模型輸出的結(jié)果顯著提升了類別分割可靠性。
4
典型場景分析本文采用的數(shù)據(jù)集測試圖像眾多,圖像中地物類型豐富,包括植被、水體、停車場,施工裸地等,有些復雜的場景給建筑提取帶來巨大挑戰(zhàn)。本文繼續(xù)分析了本文算法在一些復雜場景下的建筑提取表現(xiàn)。圖8(a)展示了ISPRS Vaihingen數(shù)據(jù)集中的一塊測試區(qū)域,該區(qū)域植被分布較多。本文注意到部分屋頂上也有植被覆蓋,這樣的建筑很難被檢測出來。此外,相鄰建筑之間的陰影遮蓋也容易造成建筑信息的遺漏。圖8(b)展示了WHU Building數(shù)據(jù)集中的一塊施工裸地區(qū)域,其中有一些建設(shè)區(qū)域與建筑特征非常相似,該區(qū)域容易造成虛警。圖8(c)展示了Massachusetts Building數(shù)據(jù)集中的一塊測試區(qū)域,該數(shù)據(jù)分辨率相對較低,相鄰的建筑物之間界限不明顯,在檢測結(jié)果中容易粘連在一起。但也注意到該區(qū)域的背景地物如水體與停車場等,本文算法能夠?qū)⑵渑c建筑較好地區(qū)分開來。綜上,本文的建筑提取結(jié)果在一些復雜場景下也存在一定的錯檢和遺漏誤差,但整體上的表現(xiàn)是合理的。

結(jié)束語
高分辨率影像建筑信息提取是遙感領(lǐng)域的研究熱點和難點,對城市規(guī)劃、環(huán)境評價具有重要作用。本文提出了一種基于深度學習概率決策融合的高分辨率影像建筑提取方法。該方法在決策層融合不同深度學習模型獨立輸出的分割概率,實現(xiàn)模型之間的優(yōu)勢互補,并采用形態(tài)學后處理操作進一步優(yōu)化建筑提取結(jié)果。實驗表明本文提出的方法在多種數(shù)據(jù)集上取得了滿意的精度,優(yōu)于單一模型的分割結(jié)果。而且,概率融合顯著提升了類別分割結(jié)果的可靠性,降低了分類不確定度。END
引用格式:王珍,張濤,丁樂樂,史芙蓉.高分辨率影像深度學習概率決策融合建筑提取[J].測繪科學,2021,46(6):93-101.
作者簡介:王珍,男,內(nèi)蒙古察右后旗人,正高級工程師,碩士,主要研究方向為工程測量、遙感圖像處理與應(yīng)用
本文鏈接:http://www.aiquka.com/blog/121.html
本文標簽:高分辨率影像











