

在Docker容器技術即將統治世界的趨勢下,作為地理遙感領域的AI處理解譯平臺,華為云GeoGenius空天地平臺,早已開始全面的云原生方向轉型。本文總結大規模遙感影像處理在云原生平臺的落地經驗,期間各種性能并發等場景優化經驗有不少借鑒意義,與各遙感同行分享。
本文作者:唐盛軍,華為云城市智能體架構師,擁有多年開發經驗,先后從事:網絡協議識別&解析、業務控制網關等網絡協議相關工作;13年開始轉戰云計算,熟悉OpenStack,CloudFoundry,Docker,Kubernetes實現原理,精通常見的物理&云網絡技術。目前負責容器業務產品化,如:遙感,基因,大數據,AI等
AI牛啊,云原生牛啊,所以1+1>2?
遙感影像,作為地球自拍照,能夠從更廣闊的視角,為人們提供更多維度的輔助信息,來幫助人類感知自然資源、農林水利、交通災害等多領域信息。
AI技術,可以在很多領域超過人類,關鍵是它是自動的,省時又省力。可顯著提升遙感影像解譯的工作效率,對各類地物元素進行自動化的檢測,例如建筑物,河道,道路,農作物等。能為智慧城市發展&治理提供決策依據。
云原生技術,近年來可謂是一片火熱。易構建,可重復,無依賴等優勢,無論從哪個角度看都與AI算法天生一對。所以大家也可以看到,各領域的AI場景,大都是將AI推理算法運行在Docker容器里面的。AI+云原生這么6,那么強強聯手后,地物分類、目標提取、變化檢測等高性能AI解譯不就手到擒來?我們也是這么認為的,所以基于AI+Kubernetes云原生,構建了支持遙感影像AI處理的空天地平臺。詳見:https://www.huaweicloud.com/product/geogenius.html
不過理想是好的,過程卻跟西天取經一般,九九八十一難,最終修成正果。
業務場景介紹
遇到問題的業務場景叫影像融合(Pansharpen),也就是對地球自拍照進行“多鏡頭合作美顏”功能。(可以理解成:手機的多個攝像頭,同時拍照,合并成一張高清彩色大圖)。
所以業務簡單總結就是:讀取2張圖片,生成1張新的圖片。該功能我們放在一個容器里面執行,每張融合后的結果圖片大約5GB。
問題的關鍵是,一個批次業務量需要處理的是3000多張衛星影像,所以每批任務只需要同時運行完成3000多個容器就OK啦。云原生YYDS!
業務架構圖示
為了幫助理解,這里分解使用云原生架構實現該業務場景的邏輯圖如下: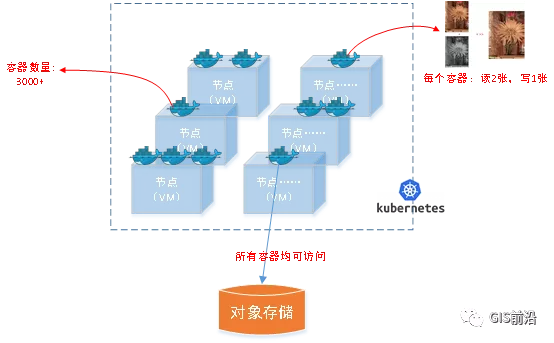
圖片
在云上,原始數據,以及結果數據,一定是要存放在對象存儲桶里面的。因為這個數據量,只有對象存儲的價格是合適的。(對象存儲,1毛錢/GB。文件存儲則需要3毛錢/GB)
因為容器之間是互相獨立無影響的,每個容器只需要處理自己的那幅影像就行。例如1號容器處理 1.tif影像;2號容器處理2.tif影像;依次類推。
所以管理程序,只需要投遞對應數量的容器(3000+),并監控每個容器是否成功執行完畢就行(此處為簡化說明,實際業務場景是一個pipeline處理流程)。那么,需求已經按照云原生理想的狀態分解,咱們開始起(tang)飛(keng)吧~
注:以下描述的問題,是經過梳理后呈現的,實際問題出現時是互相穿插錯綜復雜的。
K8s死掉了
當作業投遞后,不多久系統就顯示作業紛紛失敗。查看日志報調用K8s接口失敗,再一看,K8s的Master都已經掛了。。。
K8s-Master處理過程,總結版:
發現Master掛是因為CPU爆了
所以擴容Master節點(此處重復N次);
性能優化:擴容集群節點數量;
性能優化:容器分批投放;
性能優化:查詢容器執行進度,少用ListPod接口;
詳細版:
看監控Master節點的CPU已經爆掉了,所以最簡單粗暴的想法就是給Master擴容呀,嘎嘎的擴。于是從4U8G * 3 一路擴容一路測試一路失敗,擴到了32U64G * 3。可以發現CPU還是爆滿。看來簡單的擴容是行不通了。
3000多個容器,投給K8s后,大量的容器都處于Pending狀態(集群整體資源不夠,所以容器都在排隊呢)。而正在Pending的Pod,K8s的Scheduler會不停的輪訓,去判斷能否有資源可以給它安排上。所以這也會給Scheduler巨大的CPU壓力。擴容集群節點數量,可以減少排隊的Pod數量。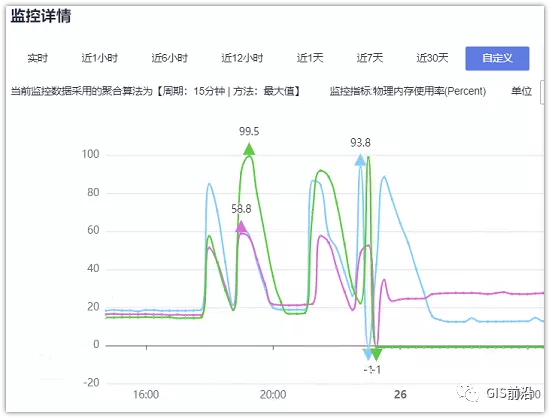
另外,既然排隊的太多,不如就把容器分批投遞給K8s吧。于是開始分批次投遞任務,想著別一次把K8s壓垮了。每次投遞數量,減少到1千,然后到500,再到100。
同時,查詢Pod進度的時候,避免使用ListPod接口,改為直接查詢具體的Pod信息。因為List接口,在K8s內部的處理會列出所有Pod信息,處理壓力也很大。
這一套組合拳下來,Master節點終于不掛了。不過,一頭問題按下去了,另一頭問題就冒出來了。
容器跑一半,掛了
雖然Master不掛了,但是當投遞1~2批次作業后,容器又紛紛失敗。
容器掛掉的處理過程,總結版:
發現容器掛掉是被eviction驅逐了;
Eviction驅逐,發現原因是節點報Disk Pressure(存儲容量滿了);
于是擴容節點存儲容量;
延長驅逐容器(主動kill容器)前的容忍時間;
詳細版:
(注:以下問題是定位梳理后,按順序呈現給大家。但其實出問題的時候,順序沒有這么友好)
容器執行失敗,首先想到的是先看看容器里面腳本執行的日志唄:結果報日志找不到~
于是查詢Pod信息,從event事件中發現有些容器是被Eviction驅逐干掉了。同時也可以看到,驅逐的原因是 DiskPressure(即節點的存儲滿了)。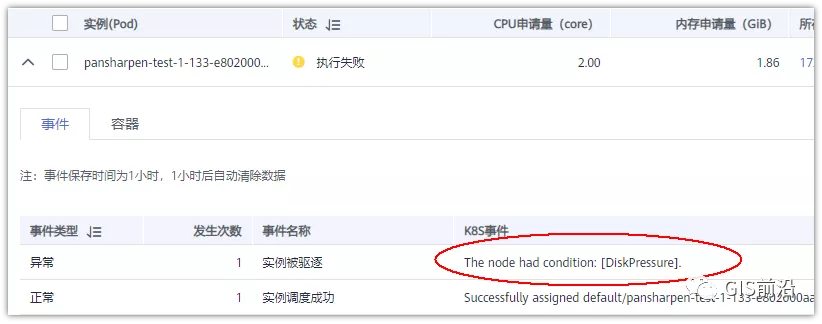
當Disk Pressure發生后,節點被打上了驅逐標簽,隨后啟動主動驅逐容器的邏輯:
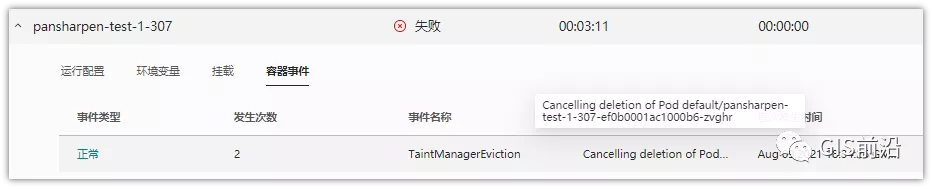
由于節點進入Eviction驅逐狀態,節點上面的容器,如果在5分鐘后,還沒有運行完,就被Kubelet主動殺死了。(因為K8s想通過干掉容器來騰出更多資源,從而盡快退出Eviction狀態)。
這里我們假設每個容器的正常運行時間為1~2個小時,那么不應該一發生驅動就馬上殺死容器(因為已經執行到一半的容器,殺掉重新執行是有成本浪費的)。我們期望應該盡量等待所有容器都運行結束才動手。所以這個 pod-eviction-timeout 容忍時間,應該設置為24小時(大于每個容器的平均執行時間)。
Disk Pressure的直接原因就是本地盤容量不夠了。所以得進行節點存儲擴容,有2個選擇:1)使用云存儲EVS(給節點掛載云存儲)。2)擴容本地盤(節點自帶本地存儲的VM)。
由于云存儲(EVS)的帶寬實在太低了,350MB/s。一個節點咱們能同時跑30多個容器,帶寬完全滿足不了。最終選擇使用 i3類型的VM。這種VM自帶本地存儲。并且將8塊NVMe盤,組成Raid0,帶寬還能x8。
對象存儲寫入失敗
容器執行繼續紛紛失敗。
容器往對象存儲寫入失敗處理過程,總結版:
不直接寫入,而是先寫到本地,然后cp過去。
將普通對象桶,改為支持文件語義的并行文件桶。
詳細版:
查看日志發現,腳本在生成新的影像時,往存儲中寫入時出錯: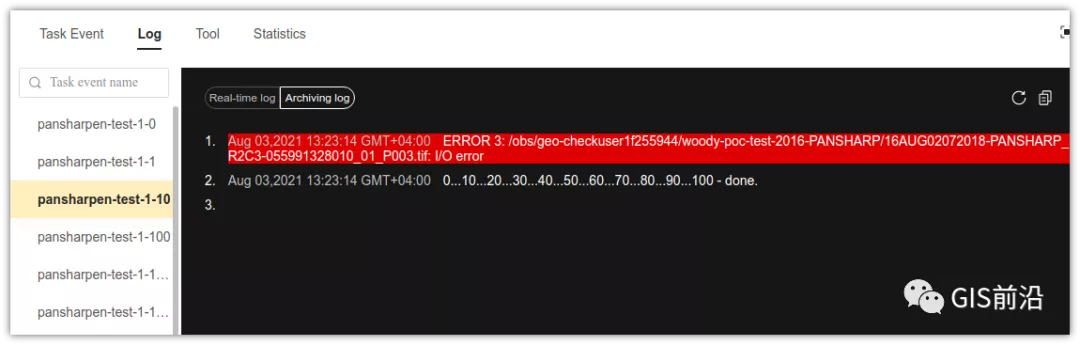
我們整集群是500核的規模,同時運行的容器數量大概在250個(每個2u2g)。這么多的容器同時往1個對象存儲桶里面并發追加寫入。這個應該是導致該IO問題的原因。
對象存儲協議s3fs,本身并不適合大文件的追加寫入。因為它對文件的操作都是整體的,即使你往一個文件追加寫入1字節,也會導致整個文件重新寫一遍。
最終這里改為:先往本地生成目標影像文件,然后腳本的最后,再拷貝到對象存儲上。相當于增加一個臨時存儲中轉一下。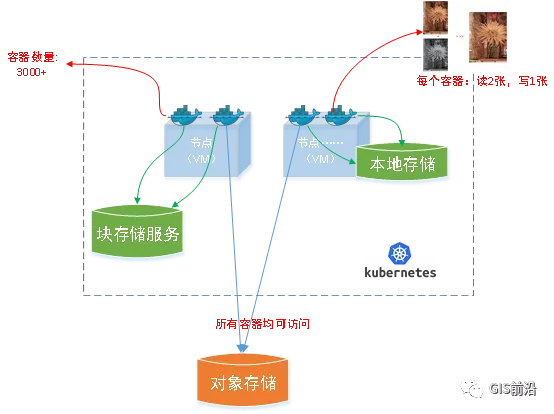
在臨時中轉存儲選擇中,2種本地存儲都試過:1)塊存儲帶寬太低,350MB/s影響整體作業速度。2)可以選擇帶本地存儲的VM,多塊本地存儲組成Raid陣列,帶寬速度都杠杠滴。
同時,華為云在對象存儲協議上也有一個擴展,使其支持追加寫入這種的POSIX語義,稱為并行文件桶。后續將普通的對象桶,都改為了文件語義桶。以此來支撐大規模的并發追加寫入文件的操作。
K8s計算節點掛了
So,繼續跑任務。但是這容器作業,執行又紛紛失敗鳥~
計算節點掛掉,定位梳理后,總結版:
計算節點掛掉,是因為好久沒上報K8s心跳了。
沒上報心跳,是因為kubelet(K8s節點的agent)過得不太好(死掉了)。
是因為Kubelet的資源被容器搶光了(由于不想容器經常oom kill,并未設置limit限制)
為了保護kubelet,所有容器全都設置好limit。
詳細版,直接從各類奇葩亂象等問題入手:
1) 容器啟動失敗,報超時錯誤。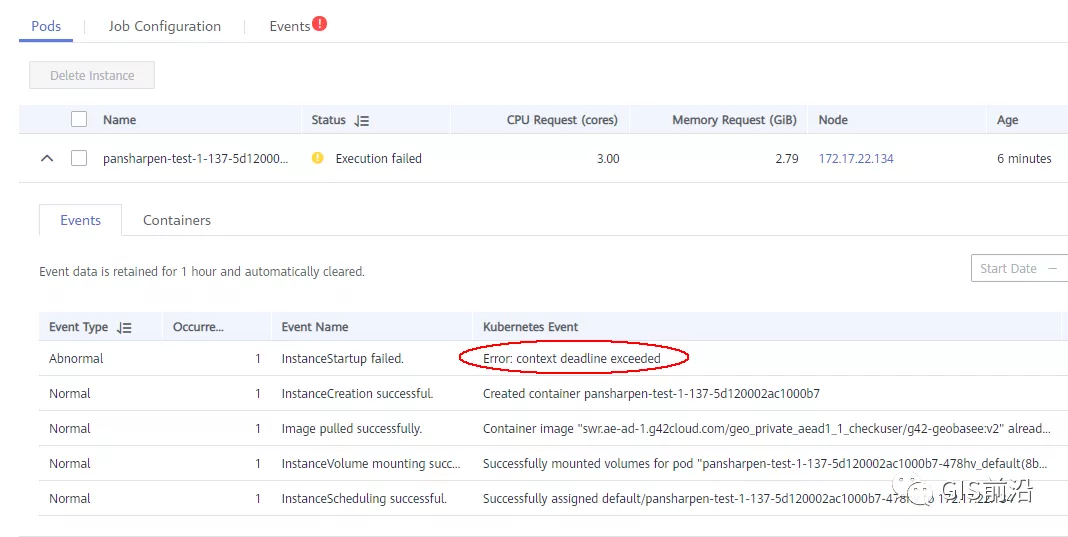
2) 然后,什么PVC共享存儲掛載失敗:
3) 或者,又有些容器無法正常結束(刪不掉)。

4) 查詢節點Kubelet日志,可以看到充滿了各種超時錯誤: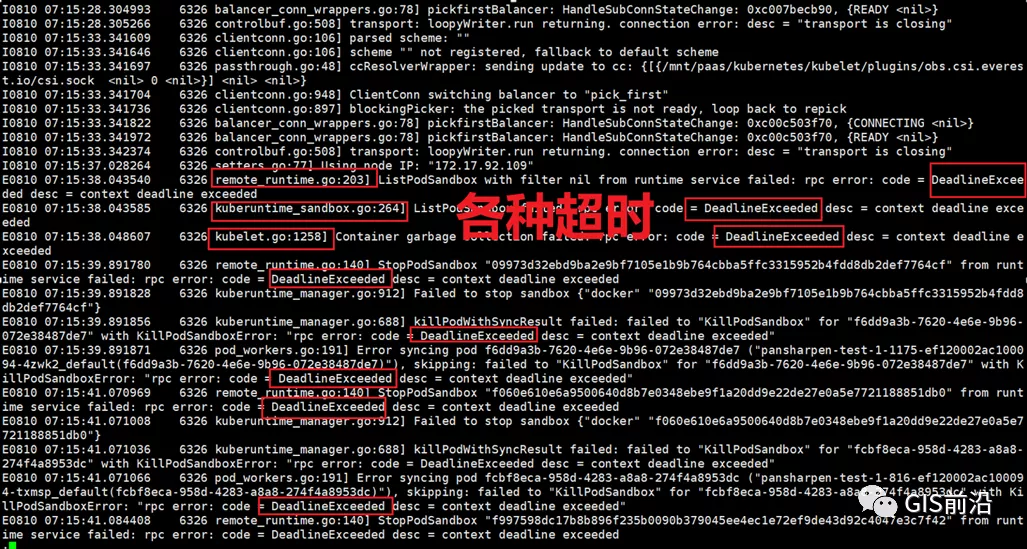
圖片
啊,這么多的底層容器超時,一開始感覺的Docker的Daemon進程掛了,通過重啟Docker服務來試圖修復問題。
后面繼續定位發現,K8s集群顯示,好多計算節點Unavailable了(節點都死掉啦)。
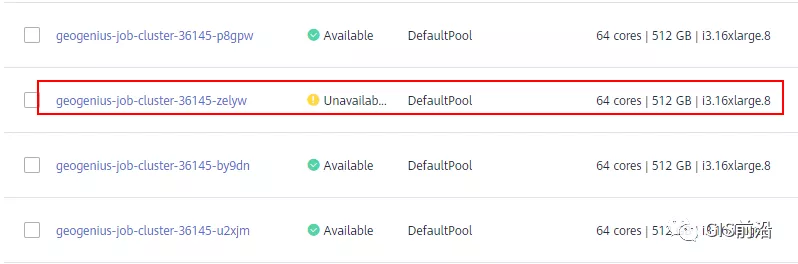
圖片
繼續分析節點不可用(Unavailable),可以發現是Kubelet好久沒有給Master上報心跳了,所以Master認為節點掛了。說明不僅僅是Docker的Daemon受影響,節點的Kubelet也有受影響。
那什么情況會導致Kubelet,Docker這些主機進程都不正常呢?這個就要提到Kubernetes在調度容器時,所設計的Request和Limit這2個概念了。
Request是K8s用來調度容器到空閑計算節點上的。而Limit則會傳遞給Docker用于限制容器資源上限(觸發上限容易被oom killer 殺掉)。前期我們為了防止作業被殺死,僅為容器設置了Request,沒有設置Limit。也就是每個容器實際可以超出請求的資源量,去搶占額外的主機資源。大量容器并發時,主機資源會受影響。
考慮到雖然不殺死作業,對用戶挺友好,但是平臺自己受不了也不是個事。于是給所有的容器都加上了Limit限制,防止容器超限使用資源,強制用戶進程運行在容器Limit資源之內,超過就Kill它。以此來確保主機進程(如Docker,Kubelet等),一定是有足夠的運行資源的。
K8s計算節點,又掛了
于是,繼續跑任務。不少作業執行又雙叒失敗鳥~
節點又掛了,總結版:
分析日志,這次掛是因為PLEG(Pod Lifecycle Event Generator)失敗。
PLEG異常是因為節點上面存留的歷史容器太多(>500個),查詢用時太久超時了。
及時清理已經運行結束的容器(即使跑完的容器,還是會占用節點存儲資源)。
容器接口各種超時(cpu+memory是有limit保護,但是io還是會被搶占)。
提升系統磁盤的io性能,防止Docker容器接口(如list等)超時。
詳細版:
現象還是節點Unavailable了,查看Kubelet日志搜索心跳情況,發現有PLEG is not healthy 的錯誤:
于是搜索PLEG相關的Kubelet日志,發現該錯誤還挺多:
圖片
這個錯誤,是因為kubelet去list當前節點所有容器(包括已經運行結束的容器)時,超時了。
看了代碼:
https://github.com/kubernetes/kubernetes/blob/master/pkg/kubelet/pleg/generic.go#L203
kubelet判斷超時的時間,3分鐘的長度是寫死的。所以當pod數量越多,這個超時概率越大。很多場景案例表明,節點上的累計容器數量到達500以上,容易出現PLEG問題。(此處也說明K8s可以更加Flexible一點,超時時長應該動態調整)。
緩解措施就是及時的清理已經運行完畢的容器。但是運行結束的容器一旦清理,容器記錄以及容器日志也會被清理,所以需要有相應的功能來彌補這些問題(比如日志采集系統等)。
List所有容器接口,除了容器數量多,IO慢的話,也會導致超時。
這時,從后臺可以看到,在投遞作業期間,大量并發容器同時運行時,云硬盤的寫入帶寬被大量占用: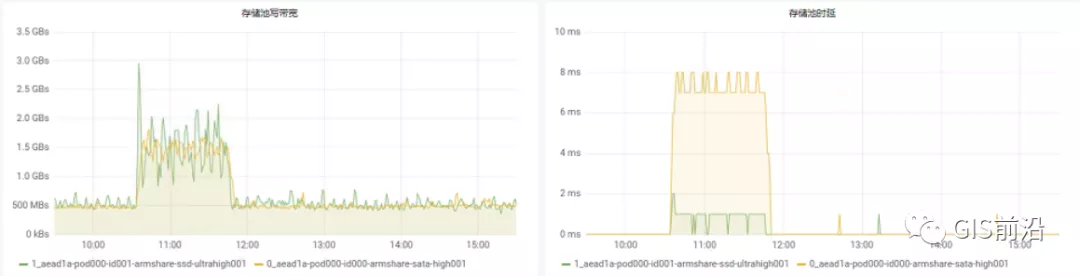
對存儲池的沖擊也很大: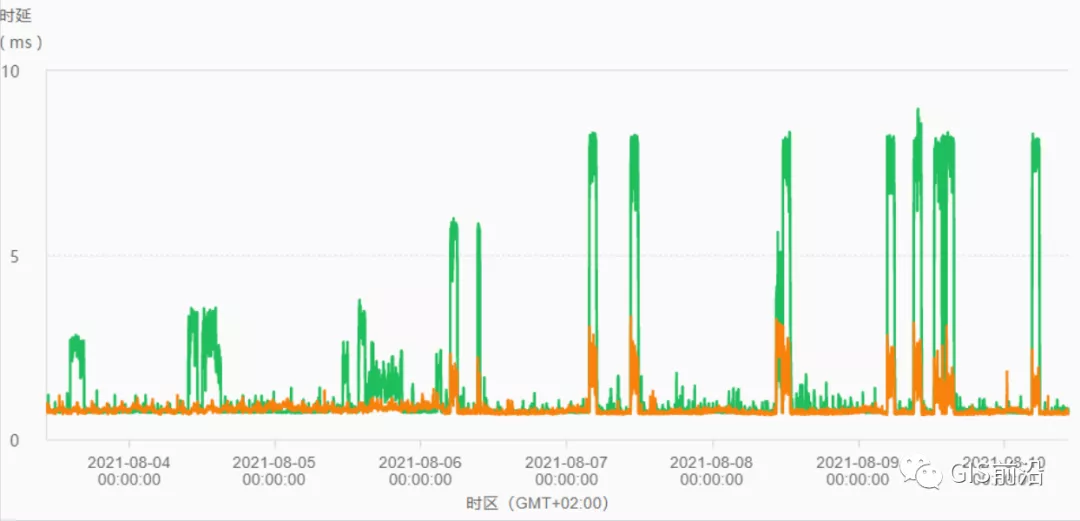
這也導致了IO性能變很差,也會一定程度影響list容器接口超時,從而導致PLEG錯誤。
該問題的解決措施:盡量使用的帶本地高速盤的VM,并且將多塊數據盤組成Raid陣列,提高讀寫帶寬。
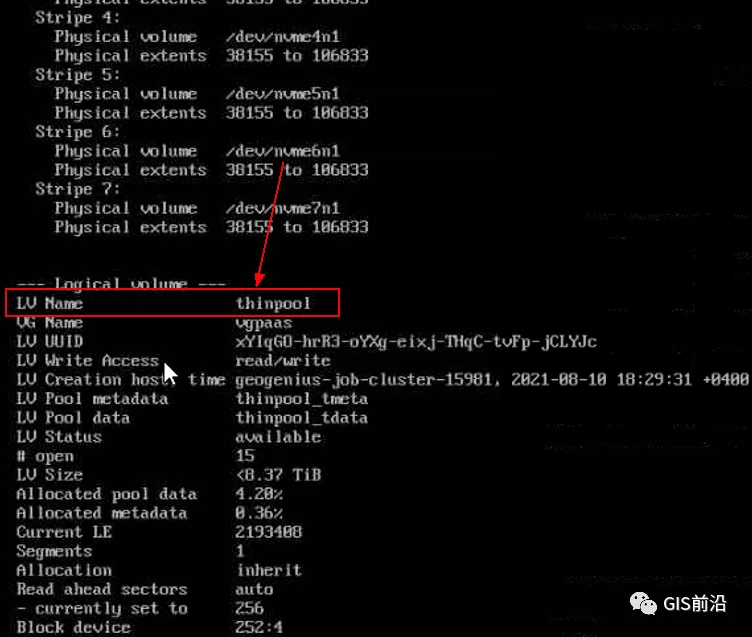
這樣,該VM作為K8s的節點,節點上的容器都直接讀寫本地盤,io性能較好。(跟大數據集群的節點用法一樣了,強依賴本地shuffle~)。
在這多條措施實施后,后續多批次的作業都可以平穩的運行完。
總結:“AI+云原生”這條路
云原生是趨勢,已經成為大家的共識,各領域也都開始以云原生為底座的業務嘗試。AI是未來,這也是當前不可阻擋的力量。但是當AI踏上這條云原生的道路卻不那么一帆風順。至少可以看到,華為云的云原生底座(當然,也包括存儲、網絡等周邊基礎設施)還可以有更多的進步空間。
但是,大家也不用擔心太多,因為當前華為云的空天地平臺,在經歷了多年的AI+云原生的積累,目前可以很穩定的處理PB級每日的遙感影像數據,支撐各類空基、天基、地基等場景,并且在該領域保持絕對領先的戰斗值。雖然大家看到此間過程有點曲折,但是所有的困難都是涅槃的火種,克服過的困難都是今后可以對客戶做的承諾。在這里可以很明確的告訴各位:AI+云原生=真香。
寫這篇文章的目的,不是在闡述困難,而是為了總結分享。與同領域的人分享并促進遙感領域的快速發展,共同推動AI+云原生的落地。
來源:https://blog.csdn.net/qq_43173805/article/details/121064717成都途遠GIS是一家專業致力于無人機航空攝影測繪、航空數據處理、GIS地理信息系統研發、數字孿生城市制作、數字沙盤模型等業務的創新型科技公司,為您提供一站式地理信息服務。
本文鏈接:http://www.aiquka.com/industry/445.html
本文標簽:遙感











